Adding generative Q&A for your documentation
Learn how to build a ChatGPT-style doc search powered using our headless search toolkit.
Supabase provides a Headless Search Toolkit for adding "Generative Q&A" to your documentation. The toolkit is "headless", so that you can integrate it into your existing website and style it to match your website theme.
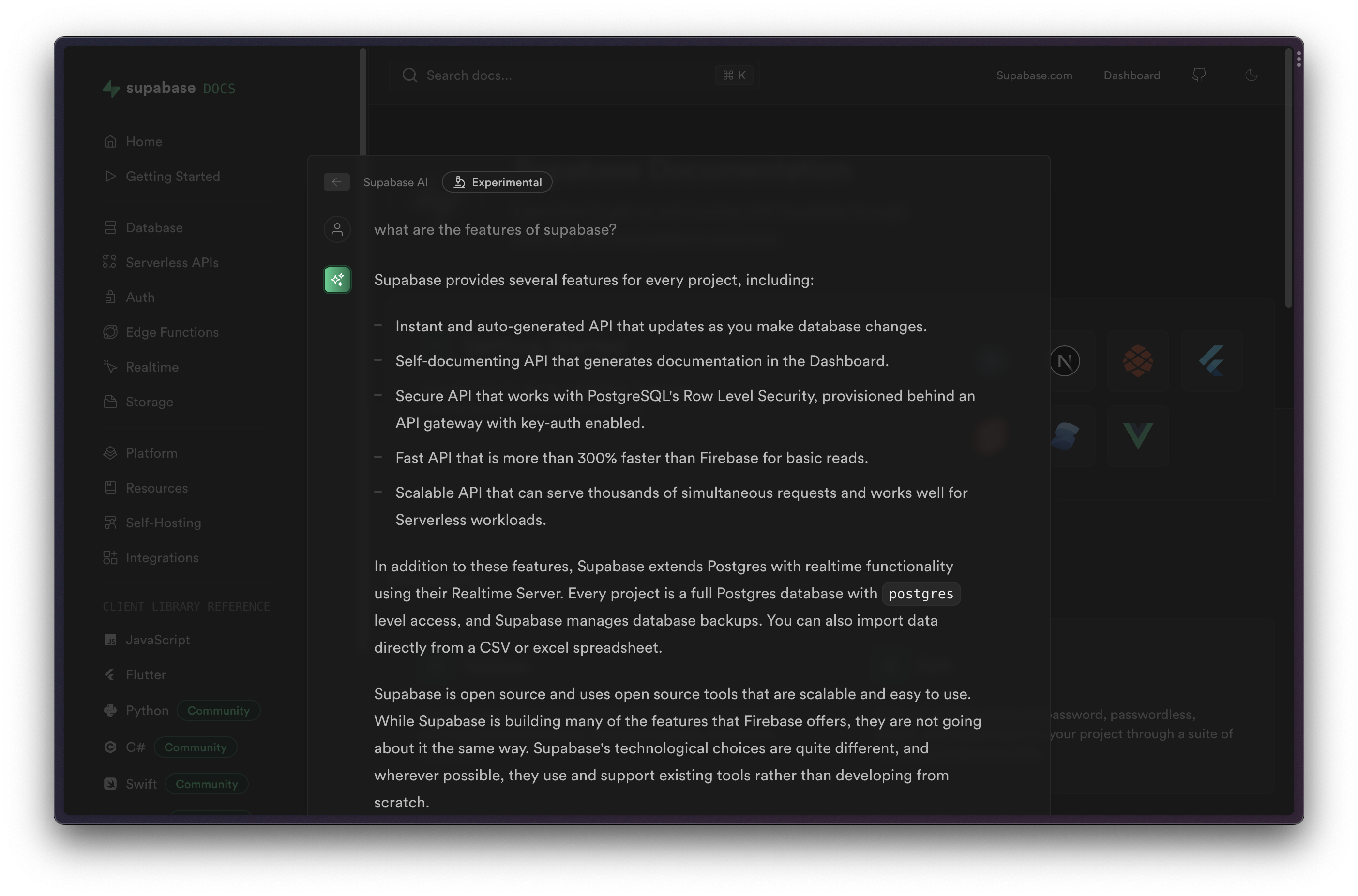
You can see how this works with the Supabase docs. Just hit cmd+k and "ask" for something like "what are the features of supabase?". You will see that the response is streamed back, using the information provided in the docs:
Tech stack
- Supabase: Database & Edge Functions.
- OpenAI: Embeddings and completions.
- GitHub Actions: for ingesting your markdown docs.
Toolkit
This toolkit consists of 2 parts:
- The Headless Vector Search template which you can deploy in your own organization.
- A GitHub Action which will ingest your markdown files, convert them to embeddings, and store them in your database.
Usage
There are 3 steps to build similarity search inside your documentation:
- Prepare your database.
- Ingest your documentation.
- Add a search interface.
Prepare your database
To prepare, create a new Supabase project and store the database and API credentials, which you can find in the project settings.
Now we can use the Headless Vector Search instructions to set up the database:
- Clone the repo to your local machine:
git clone [email protected]:supabase/headless-vector-search.git - Link the repo to your remote project:
supabase link --project-ref XXX - Apply the database migrations:
supabase db push - Set your OpenAI key as a secret:
supabase secrets set OPENAI_API_KEY=sk-xxx - Deploy the Edge Functions:
supabase functions deploy --no-verify-jwt - Expose
docsschema via API in Supabase Dashboard settings >API Settings>Exposed schemas
Ingest your documentation
Now we need to push your documentation into the database as embeddings. You can do this manually, but to make it easier we've created a GitHub Action which can update your database every time there is a Pull Request.
In your knowledge base repository, create a new action called .github/workflows/generate_embeddings.yml with the following content:
_17name: 'generate_embeddings'_17on: # run on main branch changes_17 push:_17 branches:_17 - main_17_17jobs:_17 generate:_17 runs-on: ubuntu-latest_17 steps:_17 - uses: actions/checkout@v3_17 - uses: supabase/[email protected] # Update this to the latest version._17 with:_17 supabase-url: 'https://your-project-ref.supabase.co' # Update this to your project URL._17 supabase-service-role-key: ${{ secrets.SUPABASE_SERVICE_ROLE_KEY }}_17 openai-key: ${{ secrets.OPENAI_API_KEY }}_17 docs-root-path: 'docs' # the path to the root of your md(x) files
Make sure to choose the latest version, and set your SUPABASE_SERVICE_ROLE_KEY and OPENAI_API_KEY as repository secrets in your repo settings (settings > secrets > actions).
Add a search interface
Now inside your docs, you need to create a search interface. Because this is a headless interface, you can use it with any language. The only requirement is that you send the user query to the query Edge Function, which will stream an answer back from OpenAI. It might look something like this:
_31const onSubmit = (e: Event) => {_31 e.preventDefault()_31 answer.value = ""_31 isLoading.value = true_31_31 const query = new URLSearchParams({ query: inputRef.current!.value })_31 const projectUrl = `https://your-project-ref.supabase.co/functions/v1`_31 const queryURL = `${projectURL}/${query}`_31 const eventSource = new EventSource(queryURL)_31_31 eventSource.addEventListener("error", (err) => {_31 isLoading.value = false_31 console.error(err)_31 })_31_31 eventSource.addEventListener("message", (e: MessageEvent) => {_31 isLoading.value = false_31_31 if (e.data === "[DONE]") {_31 eventSource.close()_31 return_31 }_31_31 const completionResponse: CreateCompletionResponse = JSON.parse(e.data)_31 const text = completionResponse.choices[0].text_31_31 answer.value += text_31 });_31_31 isLoading.value = true_31}
Resources
- Read about how we built ChatGPT for the Supabase Docs.
- Read the pgvector Docs for Embeddings and vector similarity
- See how to build something like this from scratch using Next.js.